性能测试全栈笔记:2.性能测试基础-指标篇
性能测试全栈笔记
二、性能测试基础
1.性能测试指标
1)事务:事务是一个点,我们为了衡量某个action的性能,在action的开始位置和结束位置插入这样的一个时间戳的范围。事务是用户定义的,想测试什么业务的性能,就把该业务加到事务中。
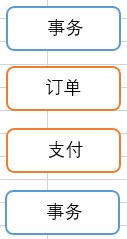
上图意思:将订单、支付作为一个事务(支付前需有订单,脚本设置前考虑关联)
2)TPS/QPS
TPS:每秒处理的事务数
全称:Transaction Per Second
对应的,QPS:每秒的请求数
3)响应时间
其实,我们更关注的是平均响应时间,后面会说
先说响应时间,这是一个比较大的概念,丢一张图方便理解

响应时间(Response Time):请求+返回数据整体时间,还得加上上图各组件的处理时间
平均响应时间(Average Response Time):整体的平均耗时,是性能测试的指标之一,常用来与90%响应时间做比较,但不用太执着,因为我们看重的还是90%响应指标
4)TOP响应时间(90%响应时间)
意思:将所有请求的响应时间先从大到小进行排序,计算指定比例的请求都是小于某个时间
举例说明:
TOP90(90%响应时间):90%的请求耗时都低于某个响应时间
TOP95(95%响应时间):95%的请求耗时都低于某个响应时间
TOP99(99%响应时间):99%的请求耗时都低于某个响应时间
其中,90%响应时间指标是我们重点关注的
问:为什么是90%?
答:业界统一(但如果所在公司有特别要求,因特殊考虑)
2.下面的指标了解即可:
1)事务响应时间:完成这个事务所用的时间
2)吞吐率:单位时间在网络上传输的数据量
3)点击率:每秒发送的http请求的数量,点击率越大server的压力也就越大
4)资源利用率:对不同资源的使用程度,比如服务器的CPU,内存等
5)并发数:压测工具中设置的并发线程数量
6)成功率:请求的成功率(对于性能,其实我们只关心成功了多少)
7)PV:页面访问量
8)UV:独立客户端数量
9)吞吐量:网络中上行和下行的流量总和,TPS越高,吞吐量越大
3.扩展知识:
问:TPS、响应时间和并发数的关系?
答:系统到达性能瓶颈前,TPS与并发数呈正比关系,即:TPS=并发数/响应时间
也就是说,随着响应时间增加,并发数增加,TPS随之增加,当然,到达瓶颈后,会趋于平稳或上下浮动
4.集合点:
比较重要的一个指标,单独说明
集合点:是一个控制真正并发访问的点,通常和事务结合起来使用,一般放在开始事务的前面,只能放在事务(action)里面
说人话:聚集一批线程,满足特定间隔要求,同时访问目标地址
问:什么时候需要加集合点?
答:根据业务选择,如果业务场景是瞬间高并发类型,如抢购、秒杀等,需要加集合点
下面,很重要的!
5.性能监控指标:
1)操作系统级别监控:
CPU使用率、内存使用率、网络IO(input/output)、磁盘(read/write/util)
2)中间件监控:
连接数、长短连接、使用内存
3)应用层监控:
线程状态、JVM参数、GC频率、锁
4)数据库监控: 连接数、锁、缓存、内存、SQL效率
纯理论,望多看,多思考,多记忆